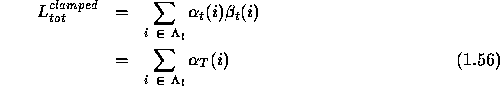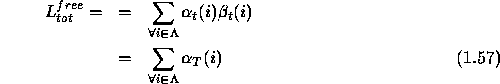To describe the MMI training procedure, we need the appropriate forms of eqns. 1.39 and 1.40.
First consider the clamped case. Since we are working in the
sentence level, we form an HMM, ![]() (by interconnecting the HMMs of speech
units) which represents a class l of sentences to which the current observation sequence
(by interconnecting the HMMs of speech
units) which represents a class l of sentences to which the current observation sequence ![]() belongs. Then starting from eqn.
1.39 ,
belongs. Then starting from eqn.
1.39 ,
where the second line follows from eqn.1.3.
For the free case, we have only one HMM, ![]() which represents the whole
language. Therefore summing up over all the alternative classes will be
equivalent to summing up over the whole set of states. Thus the eqn.
1.40, takes following form,
which represents the whole
language. Therefore summing up over all the alternative classes will be
equivalent to summing up over the whole set of states. Thus the eqn.
1.40, takes following form,
Now the MMI procedure will be as follows.
![]()