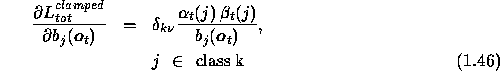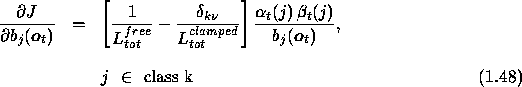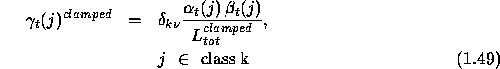Using the chain rule for any of the likelihoods, free or clamped,
Differentiating eqns.1.39 and 1.40 wrt
![]() , to get two results for free and clamped cases, and
using the common result in eqn.1.28, we get substitutions for
both terms on the right hand side of eqn. 1.45. This substitution
yields two separate results for free and clamped cases.
, to get two results for free and clamped cases, and
using the common result in eqn.1.28, we get substitutions for
both terms on the right hand side of eqn. 1.45. This substitution
yields two separate results for free and clamped cases.
where ![]() is a Kronecker delta. And
is a Kronecker delta. And
Substitution of eqns. 1.46 and 1.47 in eqn.1.38 we get the required result,
This equation can be given a somewhat ``nice'' form by defining,
where ![]() is a Kronecker delta, and
is a Kronecker delta, and
With these variables we express the eqn.1.48 in the following form.
This equation completely defines the update of observation probabilities. If however continuous densities are used then we can further propagate this derivative using the chain rule, in exactly the same way as mentioned in the case ML. A similar comments are valid also for preprocessors.