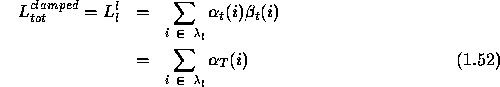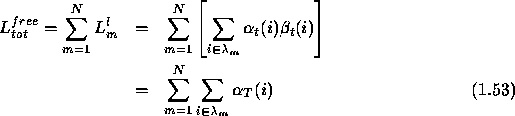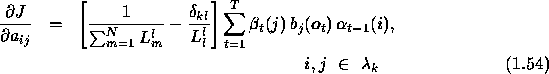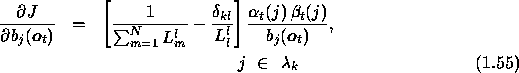We assume that the preprocessing part of the system gives out a sequence of observation vectors
![]()
Starting from a certain set of values, parameters of each of the HMMs
![]()
can be updated as given
by the eqn.1.19, while the required gradients will be given
by eqns. 1.44 and 1.48. However for this particular
case, isolated recognition, likelihoods in the the last two equations
are calculated in a peculiar way.
First consider the clamped case. Since we have an HMM for each class
of units in isolated recognition, we can select the model
![]() of the class l to which the current observation
sequence
of the class l to which the current observation
sequence ![]() belongs. Then starting from eqn.
1.39 ,
belongs. Then starting from eqn.
1.39 ,
where the second line follows from eqn.1.3.
Similarly for the free case, starting from eqn. 1.40,
where ![]() represents the likelihood of the current observation
sequence belonging to class l, in the model
represents the likelihood of the current observation
sequence belonging to class l, in the model ![]() . With those
likelihoods defined in eqns.1.52 and 1.53, the
gradient giving equations 1.44 and 1.48 will take
the forms,
. With those
likelihoods defined in eqns.1.52 and 1.53, the
gradient giving equations 1.44 and 1.48 will take
the forms,
Now we can summarize the training procedure as follows.
This procedure can easily be modified if the continuous density HMMs are used, by propagating the gradients via chain rule to the parameters of the continuous probability distributions. Further it is worth to mention that preprocessors can also be trained simultaneously, with such a further back propagation.