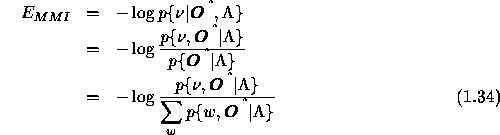In ML we optimize an HMM of only one class at a time, and do not
touch the HMMs for other classes at that time. This procedure does not
involve the concept ``discrimination'' which is of great interest in
Pattern Recognition and of course in ASR. Thus the ML learning procedure gives
a poor discrimination ability to the HMM system, specially when the
estimated parameters (in the training phase) of the HMM system do not
match with the speech inputs used in the recognition phase. This
type of mismatches can arise due to two reasons. One is that the
training and recognition data have considerably different statistical
properties, and the other is the difficulties of obtaining reliable
parameter estimates in the training.
The MMI criterion on the other hand consider HMMs of all the classes
simultaneously, during training. Parameters of the correct model are
updated to enhance it's contribution to the observations, while
parameters of the alternative models are updated to reduce their
contributions. This procedure gives a high discriminative ability to
the system and thus MMI belongs to the so called ``discriminative
training'' category.
In order to have a closer look at the MMI criterion, consider a set of
HMMs
![]()
The task is to minimize the conditional uncertainty of a class ![]() of utterances given an observation sequence
of utterances given an observation sequence ![]() of that class. This is equivalent minimize the
conditional information,
of that class. This is equivalent minimize the
conditional information,
wrt ![]() .
.
In an information theoretical frame work this leads to the
minimization of conditional entropy, defined as the expectation ( ![]() )
of the conditional information I,
)
of the conditional information I,
where ![]() represents all the classes and
represents all the classes and ![]() represents all the observation sequences.
Then the mutual information between the classes and observations,
represents all the observation sequences.
Then the mutual information between the classes and observations,
become maximized; provided ![]() is constant. This is the reason
for calling it Maximum Mutual Information (MMI) criterion. The other
name of the method, Maximum A Posteriori (MAP) has the roots in eqn.
1.31 where the a posteriori probability
is constant. This is the reason
for calling it Maximum Mutual Information (MMI) criterion. The other
name of the method, Maximum A Posteriori (MAP) has the roots in eqn.
1.31 where the a posteriori probability
![]() is maximized.
is maximized.
Even though the eqn.1.31 defines the MMI criterion, it can be rearranged using the Bayes theorem to obtain a better insight, as in eqn.1.34.
where w represents an arbitrary class.
If we use an analogous notation as in eqn.1.9, we can write the likelihoods,
In the above equations the superscripts clamped and free are used to imply the correct class and all the other classes respectively.
If we substitute eqns. 1.35 and 1.36 in the eqn.1.34, we get,
As in the case of ML re-estimation [] or gradient methods can be used
to minimize the quantity ![]() . In the following a gradient based
method, which again makes use of the eqn.1.19, is
described.
. In the following a gradient based
method, which again makes use of the eqn.1.19, is
described.
Since ![]() is to be minimized, in this case
is to be minimized, in this case
![]()
and
therefore J is directly given by eqn.1.37. The problem then
simplifies to the calculation of gradients ![]() ,where
,where ![]() is an arbitrary parameter of the whole set of
HMMs,
is an arbitrary parameter of the whole set of
HMMs, ![]() . This can be done by differentiating 1.37
wrt
. This can be done by differentiating 1.37
wrt ![]() ,
,
The same technique, as in the case of ML, can be used to compute the gradients of the likelihoods wrt the parameters. As a first step likelihoods from eqns.1.35 and 1.36, are expressed in terms of forward and backward variables using the form as in eqn.1.7.
Then the required gradients can be found by differentiating eqns. 1.39 and 1.40. But we consider two cases; one for the transition probabilities and another for the observation probabilities, similar to the case of ML.